9.1 序列类型:概述
序列的概念和分类
序列(sequence):序列是Python中最基本的数据结构,是逻辑上具有先后关系、顺序排列的一组元素。序列中的每一个元素都拥有一个序号或位置号,也称索引号或索引值。
根据序列中存储的是值还是引用,序列可分为扁平序列和容器序列。
扁平序列:存储的是值而不是引用,元素都是同一种数据类型,而且只能存储数值、字节、字符这样的基本数据类型。常见的扁平序列有:字符串str、字节bytes、数组array.array等。
容器序列:存储的是对象的引用而不是值,元素可以是任意类型的对象。常见的容器序列有:列表list和元组tuple。
根据序列是否可以被修改,序列可分为可变序列和不可变序列。
可变序列:指可以在原内存地址上对数据进行修改的序列,这类序列包括列表list、数组array.array。
不可变序列:指不可以在原内存地址上对数据进行修改的序列,这类序列包括元组tuple、字符串str、字节bytes。
9.2 序列类型:通用操作
1、遍历序列
使用实现循环结构的for语句,可以遍历序列中的每个元素。
语法格式:for 变量 in 序列
如:for i in 'abcd': for i in [1,2,3,4]:
print(i) print(i)
2、索引
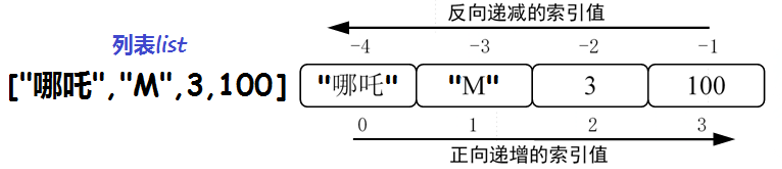
对于字符串,其中的每个字符拥有一个序号;对于元组和列表,其中的每一个元素拥有一个序号。由于序列类型中的数据项(元素)按顺序存储,因此可以使用“序号(索引值)”访问相应的数据项。
索引:通过序列数据的索引值访问其对应元素的操作。
语法格式:序列[ 索引值 ]
序列数据可同时使用两套索引体系:正向索引和逆向索引。
正向索引:正向索引使用非负索引值,序列第一个元素的索引值为0,紧跟其后元素的索引值为1,……,以此类推。
逆向索引:逆向索引使用负的索引值,序列最后一个元素的索引值为-1,倒数第二个元素的索引值为-2,……,以此类推。
3、切片
索引用于访问序列中的单个元素,要访问多个元素则可考虑使用切片。
切片:切片也叫分片,用于提取序列中一定范围内的元素。
语法格式:序列[ start:end:step]
start:指示切片开始位置的索引值,默认值为0。
end:指示切片结束位置的索引值,默认值为序列的长度。
step:步长,默认值为1。步长的正负决定了“切取方向”,正值表示从左向右取值,负值表示从右向左取值。
同之前的range对象一样,切片中包含start指示的第一个元素,但不包含end指示的最后一个元素,即切片区间[ start, end )是个左闭右开的区间,这符合计算机中以0作为起始下标的传统。
切片的过程是从第一个要返回的元素开始,到第一个不想返回的元素结束。切片操作会按照给定的索引值和步长,切取序列中的对象组成新的片段。索引操作可以视作获取只含一个元素的片段。
a.省略步长step时,默认值为1,切片操作从左向右取值。
如:s1=[1,3,5,7,9,11,13]
print(s1[1:4]
输出:[3,5,7]
b.步长step不为1,切片操作将跳过某些元素值。如下图所示,将步长step设置为2,则每隔一个元素获取内容。
如:s2=[1,3,5,7,9,11,13]
print(s1[1:6:2]
输出:[3,7,11]
c.步长不能为0,但是可以设置步长为负数。当步长为负数时,切片操作提取元素时的方向为:从右向左。
如:s3=[1,3,5,7,9,11,13,15,17,19,21,23,25,27]
print(s2[12:3:-3])
输出:[25, 19,13]

4、序列的拼接
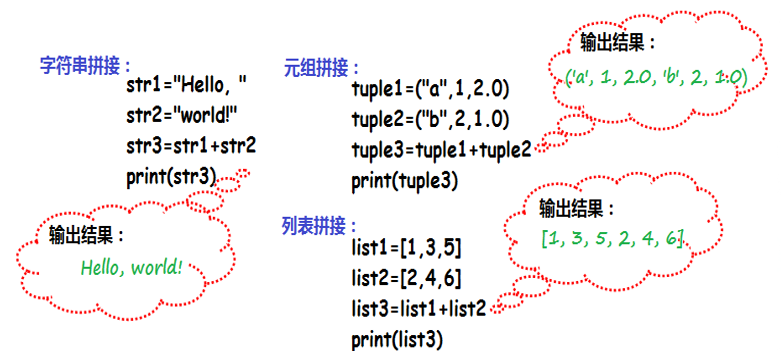
大多数序列类型,包括字符串、元组和列表,都支持序列的拼接操作。
序列拼接:该操作通过使用“+”运算符将两个相同类型的序列,连接为一个包含两个序列中全部元素的新序列。在拼接的过程中,两个进行拼接的序列都不会被修改,Python会新建一个同样类型数据的序列作为拼接的结果。
5、序列的重复
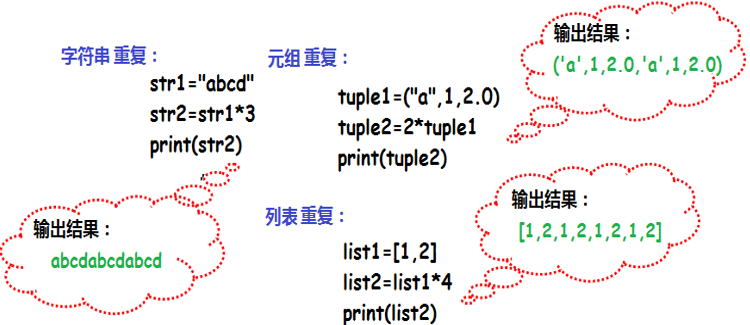
大多数序列类型,包括字符串、元组和列表,都支持序列的重复操作。
序列重复:用数字乘以(*)一个序列可以将其重复若干遍,并连接在一起形成一个新的序列。乘号两边的数据,必须一个是整数类型,一个是序列类型。在重复连接的过程中,圆序列都不会被修改,Python会新建一个同样类型数据的序列作为重复连接的结果。
6、成员测试
使用in运算符,可以检查一个值(或对象)的成员资格,也就是判断该值是否在序列中。运算的结果是布尔值:True(在序列中)或False。
使用 not in运算符检查成员资格时,运算的结果为或False时表示测试对象在序列中,True则表示不在序列中。
成员资格的检查:对于列表和元组来说,检查的是对象是否是序列的一个元素;对字符串而言,它的每一个元素就是一个字符,字符串中的每一个字符都具有成员资格,同时字符串的子串也具有成员资格。使用in运算符可以判断一个字符串是否为另一个字符串的子串。空字符串是任何字符串的子串。

7、序列长度和最值的计算
Python的内置函数可用于序列类型数据的长度和最值计算,其中:
len()函数:返回序列的长度(序列的长度即序列中元素的个数)。
min()函数:返回序列的最小元素。
max()函数:返回序列的最大元素。

8、序列中元素的统计和查找
序列的count方法,可以统计元素x在序列中出现的总次数,其语法格式为:序列.count(x)
序列的index方法,可以在序列中找出其值为x的元素首次出现的位置,其语法格式为:序列.index(x, start, end)
index方法的start和end参数指定查找的范围,与切片中两参数的含义相同。若无法找到指定元素,程序将会产生一个ValueError错误,所以在查找之前应用count方法判断一下,确保序列中存在指定元素。

9.3 随机数:random模块
1、计算机中的随机数
随机数在统计学、密码学、计算机模拟和仿真等诸多领域有着非常广泛的应用。真正的随机数都是用物理方法产生的,如掷硬币、投骰子、转轮、使用电子器件的噪声,核裂变等。
计算机中的随机数是伪随机数。科学家早已证明,仅依靠算法是无法生成真随机数的,因此凡采用一定的算法通过程序生成的都是伪随机数。虽然是伪随机数,但也能够应用于绝大多数需要随机数的场合。
2、产生随机数序列的算法和种子
有多种产生随机数序列的算法。无论使用何种算法生成随机数时,都需要一个“种子”。种子是算法开始计算随机数序列时使用的初值。若随机数的种子一样,那么每次产生的随机数序列都是一样的。如果不设置产生随机数的种子,算法一般会采用机器的系统时间作为种子,这样每次产生的随机数序列就不一样了。一般调试程序时纠错时,都选择同样的种子生成随机数,以方便程序的测试和诊断。Python使用random模块产生各种分布的随机数序列。
3、random模块中的主要函数

示例1:随机数应用示例

9.4 程序举例
示例1:输出星期几

示例2:回文字符串

示例3:提取身份证信息

示例4:IP地址格式转换
